AWSを使ってRubyによるクローラーを作ってみました
キーワード:AmazonWebServices , TechBlog , クラウドサーバー
![]() ニュースやトレンドをキャッチするためにウェブサイトを閲覧したりしますが、これを自動で出来ると便利です。Rubyでクローラーを作ればウェブサイトをアプリが自動で巡回し情報収集します。そこで今回は、AWSを使ってRubyによるクローラーを作ってみました。内容はAWSを使っていますので、アマゾンの書籍情報を常時監視し、新刊情報があれば情報収集し取得するというものです。Rubyの実行環境を構築し、AWSのスクリプトを起動した所、新刊情報を収集できました。
ニュースやトレンドをキャッチするためにウェブサイトを閲覧したりしますが、これを自動で出来ると便利です。Rubyでクローラーを作ればウェブサイトをアプリが自動で巡回し情報収集します。そこで今回は、AWSを使ってRubyによるクローラーを作ってみました。内容はAWSを使っていますので、アマゾンの書籍情報を常時監視し、新刊情報があれば情報収集し取得するというものです。Rubyの実行環境を構築し、AWSのスクリプトを起動した所、新刊情報を収集できました。
目次
1. AWSの環境設定
2.Rubyによるクローラーの開発
3. まとめ
1.AWSの環境設定
私はAWSに加入し自宅に開発環境を構築して、様々なソフトウェアを開発しています。
今回はRubyによるクローラーを作成し、ウェブサイトを巡回して自動収集してみます。情報収集する対象は、ブログやニュースなどたくさんありますが、AWSですのでアマゾンのサイトから書籍の新刊情報を自動で取得できるアプリを作ってみます。
Rubyによるクローラーはサーバー上に置きます。データを大量に取得するため、クラウド上のストレージ(ネットワークディスク)を利用します。そのためまずはストレージサービス利用の手続きです。ストレージ利用の権限を付与し、Bucketを作成します。Bucket作成時にデータを保管する地域を選びます。日本が安全、かつ地理的に近いので通信遅延も少ないのではないかと考え、日本を選びました。後で知ったのですが地域で価格差があり、なぜかアメリカよりも日本の方が価格が高めのようです。それはさておき、準備が整いましたので、Rubyによるクローラーの開発に着手します。
2.Rubyによるクローラーの開発
Rubyを実行するため、サーバー上にAWSのSDKをインストールします(図1)。実行環境はこれで完了です。
次にRubyによるクローラーを開発します。Amazonのウェブサイトから書籍の新刊情報のリストを定期的に収集するという内容です。アマゾンの新刊・予約ページのURLからパラメータを解釈し、カテゴリーと期間のIDを調べます。カテゴリーはコンピュータ・ITの書籍を抽出することにします。コンピュータ・ITカテゴリーのIDは466298でした。次に期間は、過去3日のIDが2315442051、過去一週間のIDが2315443051でした。コンピュータ・ITカテゴリーは頻繁に新刊が出るわけではないので、過去一週間に新刊を取得することにします。Rubyによるクローラーをコーディングします(図2)。カテゴリーと検索期間に先程調べたIDを記入し、収集した結果をストレージに保存するようにします。コードは完成しましたので、クローラーをサーバーに転送します。
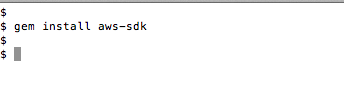
(図1)SDKインストール
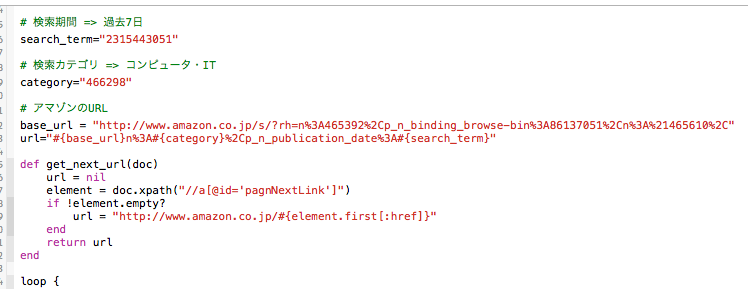
(図2)クローラーのコード
準備は整いましたので、サーバーのRubyクローラーを実際に動かしてみました。見事、新刊書籍の情報は収集できましたが、速度が数秒かかり非常に遅いです。ストレージがローカルではなくネットワークにあるため処理に時間がかかるようです。短周期で取り込むことはできそうにありません。
3.まとめ
以上、AWSを使ってRubyによるクローンを作ってみました。AWSを利用していますので、アマゾンの書籍の新刊情報を自動で巡回し、情報収集してみました。新刊情報は収集できましたが、課題がありました。大量のデータを取得する場合、ストレージが必要ですが、このストレージがネットワーク上にあるため、通信上の問題で処理の遅延が起きています。根本的な対策はありませんが、多少の回避策として、アプリの分散処理や並列処理などが必要です。